
BigQuery 支援多種 schema 變更的操作,像是:
然而,這些改動多屬於 即時修改,缺乏 schema version 控管 與 歷史回溯 ,在需要頻繁改動 schema 之開發流程中,仍可能成為維運上的痛點。
相較之下,Iceberg 在 schema evolution 的處理上更進一步。它不僅支援常見的欄位新增、刪除、重命名,還會針對每一次變更保留 schema metadata 的歷史版本,能讓我們明確掌握 schema 的演進過程。
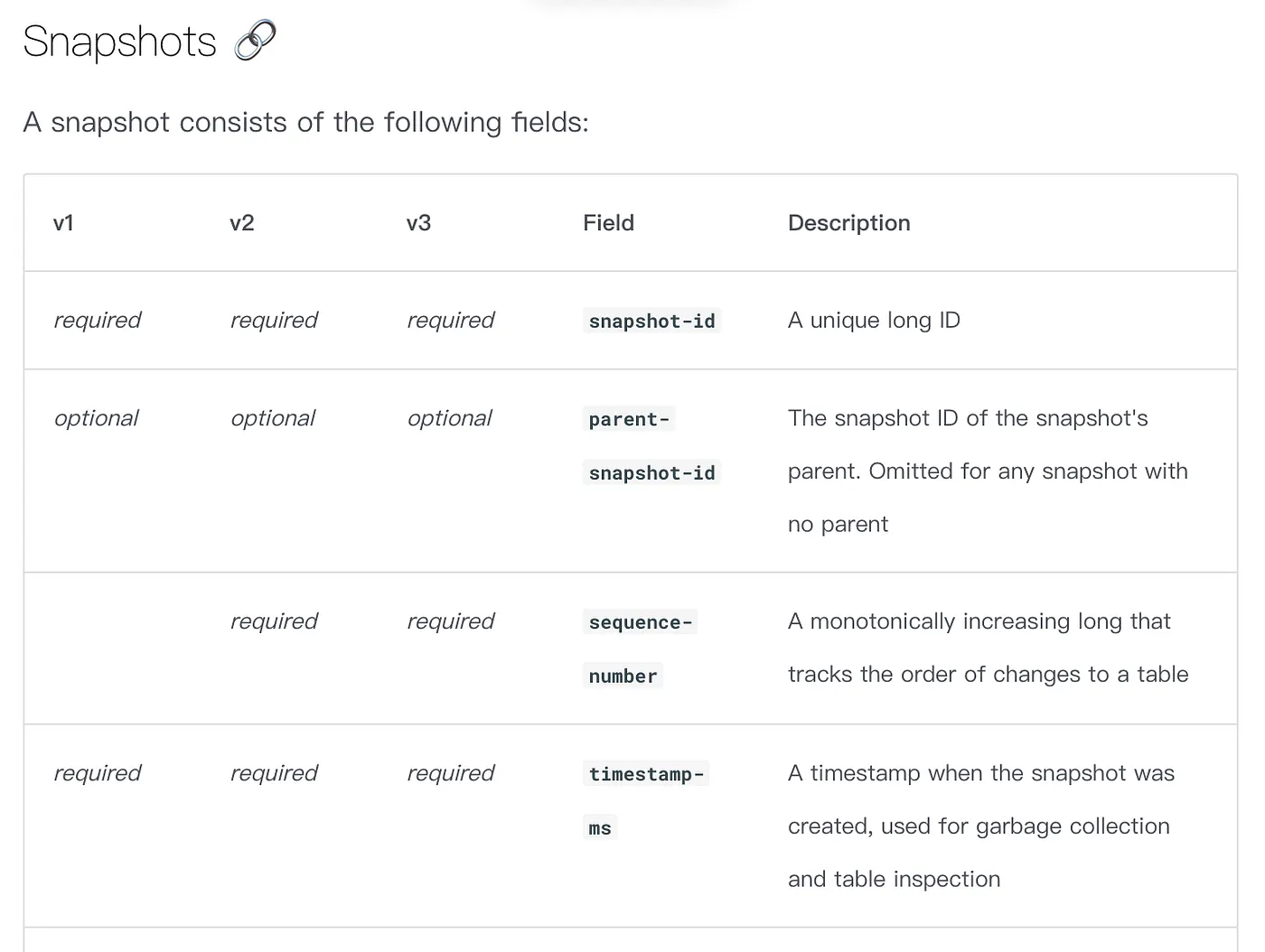
Trino 也能透過 Iceberg metadata 表 ( 如 $history 、 $snapshots ) ,查到所需 snapshot 資訊後再往下細查,實現「類 git 」資料 schema 管理。
-- $history 查詢 snapshot 資訊
SELECT * FROM "test_table$history";
-- $snapshots 查詢 snapshot 資料
SELECT * FROM "test_table$snapshots";
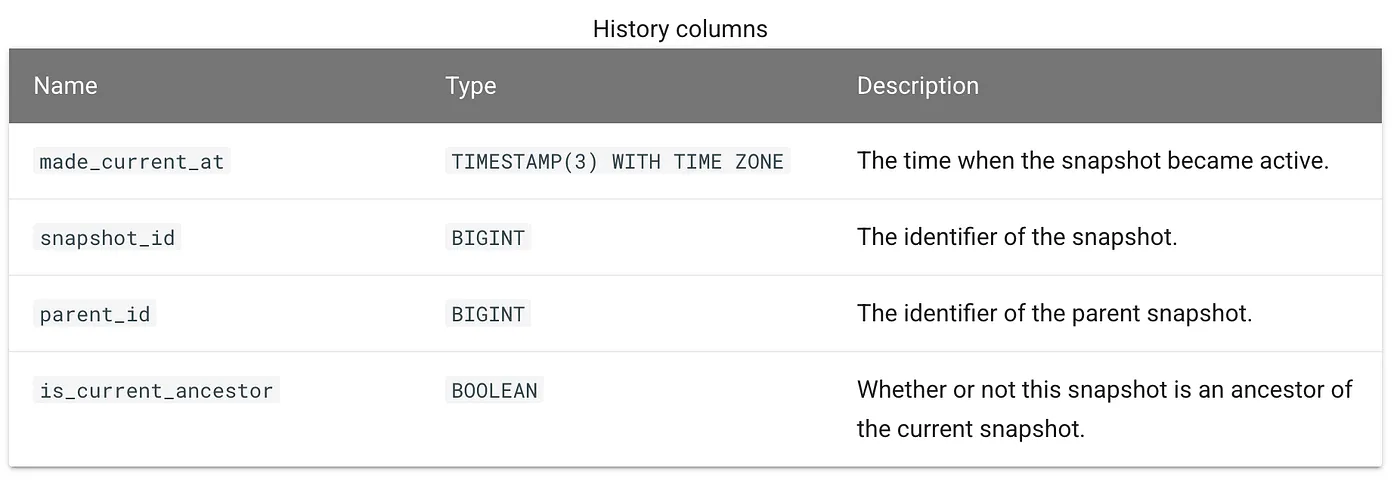

這對筆者的團隊來說很關鍵 — 例如 在開發消費者分析資料時,常會隨著業務需求調整欄位定義,甚至針對不同環境而有差異。
有了 Iceberg 的 schema versioning,不僅讓 schema 演進變得有跡可循,也讓錯誤 rollback 變得簡單,也大幅降低 維運風險 與 開發負擔。
另一個 Iceberg 帶來的實質好處是支援 增量查詢 (Incremental Read)。
這讓我們在處理較大的 Transaction table ( 如 訂單明細, 行為記錄 ) 時,無需每次都全表掃描,而是根據 Snapshot 或 資料變動,鎖定變動部分進行查詢或同步:
1️⃣ 查詢歷史 snapshot
SELECT snapshot_id, committed_at
FROM my_table$snapshots ORDER BY committed_at DESC;
2️⃣ 找出最新 snapshot 對應的 manifests
SELECT * FROM my_table$manifests WHERE snapshot_id = <latest snapshot_id>;
3️⃣ 查詢這些 manifests 中實際變動的 data files
SELECT * FROM my_table$files WHERE manifest_path IN (...);
4️⃣ 使用 partitions 進一步收斂 ETL 處理範圍
SELECT * FROM my_table$partitions;
Trino 雖未提供 Iceberg 原生增量查詢語法 ( 如 CHANGES() ),但使用 $snapshots → $manifests → $files → $partitions 這套邏輯查詢,我們可以建立差異偵測機制,有效判斷哪些 partition 或檔案需要被處理,達成:
補上 Schema Evolution 與 Incremental Read 這兩個尚未填補的空缺後,《為什麼我改用 Iceberg》系列也算正式告一段落。
明日起將展開全新篇章——《Trino + Iceberg ELT 實作 (一)》,筆者會先介紹公司內部的 ELT 架構,為後續關於 Trino + Iceberg ELT 實作細節的文章奠定理解基礎。
My Linkedin: https://www.linkedin.com/in/benny0624/
My Medium: https://hndsmhsu.medium.com/

